
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Portfolio item number 2
Short description of portfolio item number 2 
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
Control Theory for Learning
Using control theory for robust fine-tuning 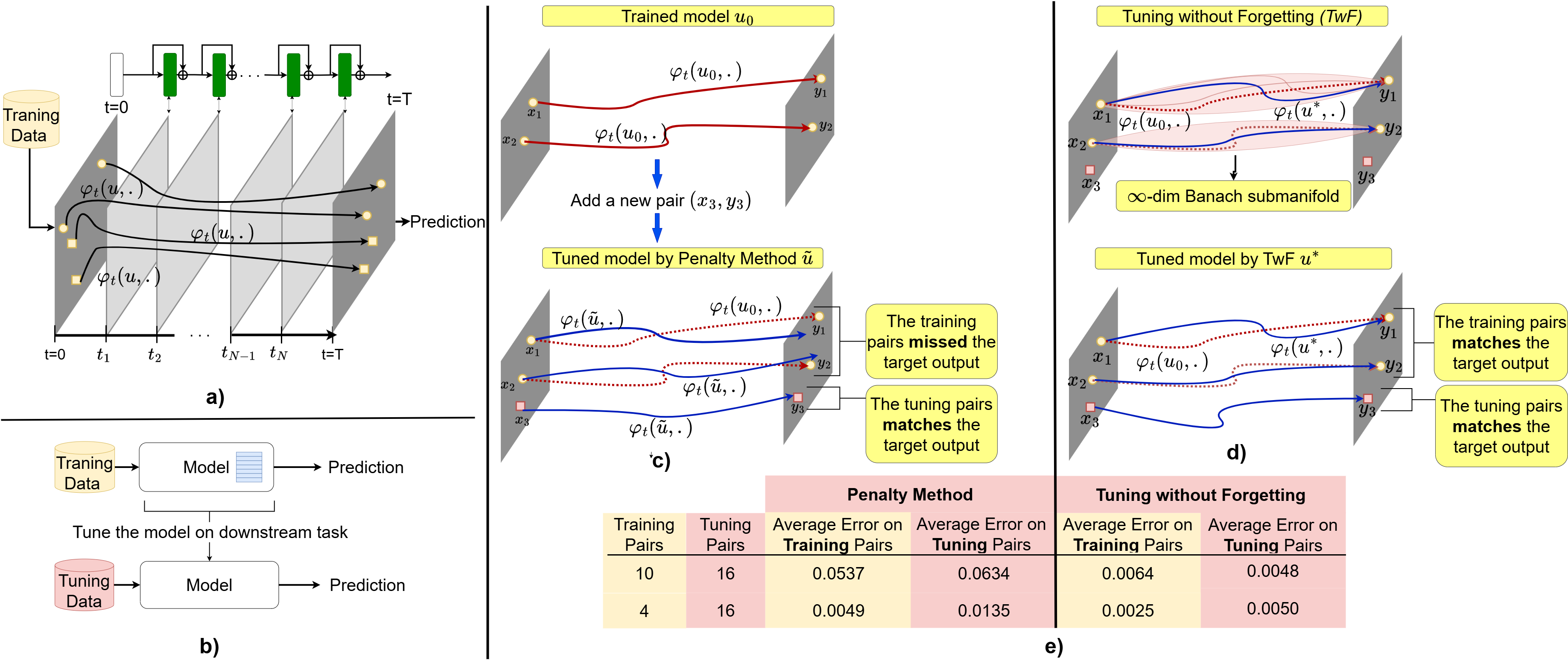
Injury Prevention via sEMG
Predict and prevent lower extremity injuries in professional athletes using sEMG data. 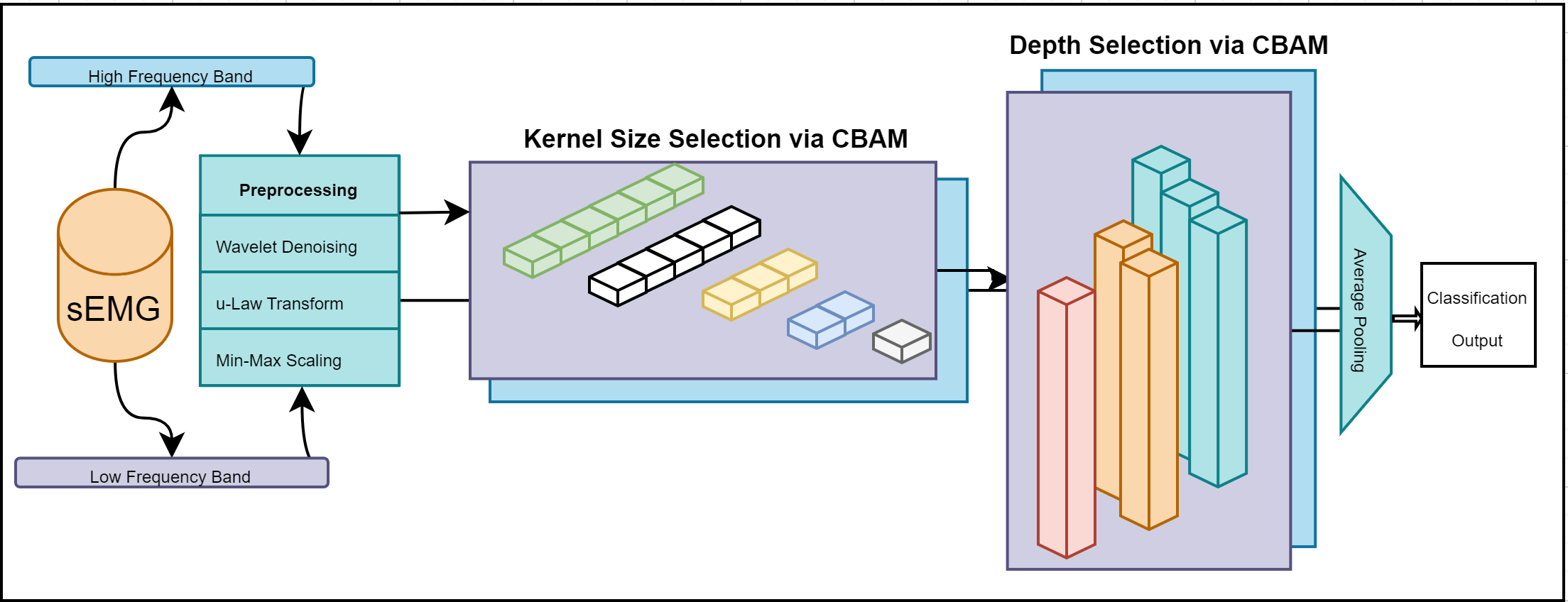
Communication on Gossip Networks
Analyze communication on gossip networks 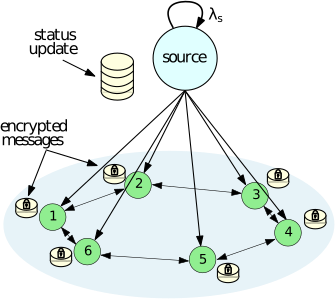
publications
sEMG Motion Classification Via Few-Shot Learning With Applications To Sports Science
Published in prePrint, 2023
Motion classification with surface electromyog-raphy (sEMG) has been studied for practical applications in prosthesis limb control and human-machine interaction. Recent studies have shown that feature learning with deep neural networks (DNN) reaches considerable accuracy in motion classification tasks. However, DNNs require large datasets for acceptable performance and fail for tasks with few data samples available for training. Professional athlete training includes hundreds of exercises, and coupled with privacy and confidentiality issues acquiring a large dataset for all the exercises is not feasible. As a result, state-of-the-art DNN architectures are unsuitable for real-life sports applications. We utilise few-shot learning (FSL) techniques to overcome the small dataset problem of sports-related motion classification tasks. The employed methodology uses the knowledge gathered from a large set of tasks to classify unseen tasks with a few data samples. The FSL approach with a siamese network and triplet loss reached the best performance with a median F1-score of 72.01%, 76%, and 79% for 1, 5 and 10 shot datasets that include an unseen set of tasks, respectively. In contrast, DNN with transfer learning (TF) reached 49.27%, 51.58%, and 67.66% for the same set of tasks, respectively.
Recommended citation: M. Ergeneci, E. Bayram, D. Binningsley, D. Carter and P. Kosmas, "sEMG Motion Classification Via Few-Shot Learning With Applications To Sports Science." Authorea Preprints (2023 https://www.techrxiv.org/doi/full/10.36227/techrxiv.22577374.v1
Vector-Valued Gossip over w-Holonomic Networks
Published in (under review), 2023
We study the weighted average consensus problem for a gossip network of agents with vector-valued states. For a given matrix-weighted graph, the gossip process is described by a sequence of pairs of adjacent agents communicating and updating their states based on the edge matrix weight. Our key contribution is providing conditions for the convergence of this non-homogeneous Markov process as well as the characterization of its limit set. To this end, we introduce the notion of “w-holonomy” of a set of stochastic matrices, which enables the characterization of sequences of gossiping pairs resulting in reaching a desired consensus in a decentralized manner. Stated otherwise, our result characterizes the limiting behavior of infinite products of (non-commuting, possibly with absorbing states) stochastic matrices.
Recommended citation: Vector-Valued Gossip over $w$-Holonomic Networks E. Bayram, M.-A. Belabbas, T. Başar - arXiv preprint arXiv:2311.04455, 2023 https://arxiv.org/abs/2311.04455
Attention-Enhanced Frequency-Split Convolution Block for sEMG Motion Classification: Experiments on Premier League and Ninapro Datasets
Published in IEEE Sensor, 2023
This article presents convolutional octave-band zooming-in with depth-kernel attention learning (COZDAL), a versatile deep learning model designed for surface electromyography (sEMG) motion classification. Specifically focusing on sports movements involving the hamstring muscle, the model employs attention mechanisms across various frequency bands, kernel sizes, and hidden layer depths. The proposed method has been extensively evaluated on the benchmark Ninapro dataset and a custom soccer dataset. The results demonstrate substantial improvements over the existing state-of-the-art models, with an accuracy of 95.30% on Ninapro DB2, outperforming the previous best by 3.29%, and an accuracy of 98.80% on Ninapro DB2-B, an 8.66% enhancement. Remarkably, COZDAL exhibits a performance accuracy of 96.30% on a soccer dataset gathered from 45 elite-level athletes representing two clubs in the English Premier League (EPL). This result, achieved without parameter tuning, highlights the model’s adaptability and exceptional efficacy across diverse motion scenarios, sensors, subjects, and muscle types.
Recommended citation: M. Ergeneci, E. Bayram, D. Binningsley, D. Carter and P. Kosmas, "Attention-Enhanced Frequency-Split Convolution Block for sEMG Motion Classification: Experiments on Premier League and Ninapro Datasets," in IEEE Sensors Journal, vol. 24, no. 4, pp. 4821-4830, 15 Feb.15, 2024, doi: 10.1109/JSEN.2023.3345731. https://ieeexplore.ieee.org/abstract/document/10375923
Age of k-out-of-n Systems on a Gossip Network
Published in 58th Asilomar Conference on Signal, Systems and Computer 24, 2024
We consider information update systems on a gossip network, which consists of a single source and n receiver nodes. The source encrypts the information into n distinct keys with version stamps, sending a unique key to each node. For decoding the information in a k-out-of-n system, each receiver node requires at least k+1 different keys with the same version, shared over peer-to-peer connections. Each node determines k based on a given function, ensuring that as k increases, the precision of the decoded information also increases. We consider two different schemes: a memory scheme (in which the nodes keep the source’s current and previous encrypted messages) and a memoryless scheme (in which the nodes are allowed to only keep the source’s current message). We measure the ‘‘timeliness’’ of information updates by using the k-keys version age of information. Our work focuses on determining closed-form expressions for the time average age of information in a heterogeneous random graph under both with memory and memoryless schemes.
Recommended citation: E. Bayram, M. Bastopcu, M. -A. Belabbas and T. Başar, "Age of k-Out-of-n Systems on a Gossip Network," 2024 58th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 2024, pp. 1807-1811 https://ieeexplore.ieee.org/document/10942930
Control Theoretic Approach to Fine-Tuning and Transfer Learning
Published in Accepted for SysDO24, 2024
Given a training set in the form of a paired (X,Y), we say that the control system x˙=f(x,u) has learned the paired set via the control u∗ if the system steers each point of X to its corresponding target in Y. Most existing methods for finding a control function u∗ require learning of a new control function if the training set is updated. To overcome this limitation, we introduce the concept of tuning without forgetting. We develop an iterative algorithm to tune the control function u∗ when the training set expands, whereby points already in the paired set are still matched, and new training samples are learned. More specifically, at each update of our method, the control u∗ is projected onto the kernel of the end-point mapping generated by the controlled dynamics at the learned samples. It ensures keeping the end points for the previously learned samples constant while iteratively learning additional samples. Our work contributes to the scalability of control methods, offering a novel approach to adaptively handle training set expansions.
Recommended citation: Control Theoretic Approach to Fine-Tuning and Transfer Learning E Bayram, S Liu, MA Belabbas, T Başar - arXiv preprint arXiv:2404.11013, 2024 https://arxiv.org/abs/2404.11013
A Novel Framework for Motion-Induced Artefact Cancellation in sEMG: Evaluation on English Premier League and Ninapro Datasets
Published in IEEE Sensor, 2024
This paper addresses the challenge posed by Motion-Induced Artifact (MIA) in surface electromyography (sEMG) signals, a prevalent issue in professional sports settings due to the movements and collisions of athletes. The shared frequency spectra and non-stationary characteristics of MIA and sEMG, coupled with the unpredictable and impulsive occurrence of MIA, cause substantial challenges to conventional filtering and signal processing-based denoising methods. This study proposes a framework involving two consecutive models specifically designed to detect MIA zones in the sEMG stream and to denoise MIA. Employing two distinct deep learning models for each task proves more effective than using a singular model, enhancing the signal-to-noise ratio (SNR) by $3.12$dB. A BLSTM RNN-based approach is proposed for detecting MIA zones, achieving macro F1 scores of $94.8\%$ and $95\%$ for synthetic and real-world datasets, respectively. This study utilizes the publicly available Ninapro dataset, enriched with synthetic MIA, and a unique dataset collected from English Premier League (EPL) athletes, incorporating real MIA. For the denoising of MIA, a novel convolution block within the U-net Encoder Decoder (UED) is introduced, featuring attention-enhanced kernel and channel selection, which achieves an SNR improvement of $17.20$dB. This approach surpasses the best state-of-the-art model by $7.01$dB and exceeds the average of contemporary models by $12$dB, signifying a substantial advancement in the field.
Recommended citation: https://ieeexplore.ieee.org/document/10542637
Geometric Foundations of Tuning without Forgetting in Neural ODEs
Published in Under Review, 2024
In our earlier work, we introduced the principle of Tuning without Forgetting (TwF) for sequential training of neural ODEs, where training samples are added iteratively and parameters are updated within the subspace of control functions that preserves the end-point mapping at previously learned samples on the manifold of output labels in the first-order approximation sense. In this letter, we prove that this parameter subspace forms a Banach submanifold of finite codimension under nonsingular controls, and we characterize its tangent space. This reveals that TwF corresponds to a continuation/deformation of the control function along the tangent space of this Banach submanifold, providing a theoretical foundation for its mapping-preserving (not forgetting) during the sequential training exactly, beyond first-order approximation.
Recommended citation: Geometric Foundations of Tuning without Forgetting in Neural ODEs E Bayram, MA Belabbas, T Başar - arXiv preprint arXiv:2509.03474, 2025 https://arxiv.org/abs/2509.03474
Age of Coded Updates In Gossip Networks Under Memory and Memoryless Schemes
Published in (Under review), 2024
We consider an information update system on a gossip network, where a source node encodes information into $n$ total keys such that any subset of at least $k+1$ keys can fully reconstruct the original information. This encoding process follows the principles of a $k$-out-of-$n$ threshold system. The encoded updates are then disseminated across the network through peer-to-peer communication. We have two different types of nodes in a network: subscriber nodes, which receive a unique key from the source node for every status update instantaneously, and nonsubscriber nodes, which receive a unique key for an update only if the node is selected by the source, and this selection is renewed for each update. For the message structure between nodes, we consider two different schemes: a memory scheme (in which the nodes keep the source’s current and previous encrypted messages) and a memoryless scheme (in which the nodes are allowed to only keep the source’s current message). We measure the \emph{timeliness} of information updates by using a recent performance metric, the version age of information. We present explicit formulas for the time average AoI in a scalable homogeneous network as functions of the network parameters under a memoryless scheme. Additionally, we provide strict lower and upper bounds for the time average AoI under a memory scheme.
Recommended citation: E. Bayram, M. Bastopcu, M. -A. Belabbas and T. Başar, "Age of Coded Updates In Gossip Networks Under Memory and Memoryless Schemes," in IEEE Transactions on Communications, 2025 https://ieeexplore.ieee.org/document/11106450
Constructing Stochastic Matrices for Weighted Averaging in Gossip Networks
Published in NecSys 25, 2025
The convergence of the gossip process has been extensively studied; however, algorithms that generate a set of stochastic matrices, the infinite product of which converges to a rank-one matrix determined by a given weight vector, have been less explored. In this work, we propose an algorithm for constructing (local) stochastic matrices based on a given gossip network topology and a set of weights for averaging across different consensus clusters, ensuring that the gossip process converges to a finite limit set.
Recommended citation: E Bayram, MA Belabbas, "Constructing Stochastic Matrices for Weighted Averaging in Gossip Networks", 10th IFAC Conference on Networked Systems NECSYS 2025, Hong-Kong. https://www.sciencedirect.com/science/article/pii/S2405896325003957
Control Disturbance Rejection in Neural ODEs
Published in To appear at CDC, 2025
In this paper, we propose an iterative training algorithm for Neural ODEs that provides models resilient to control (parameter) disturbances. The method builds on our earlier work Tuning without Forgetting-and similarly introduces training points sequentially, and updates the parameters on new data within the space of parameters that do not decrease performance on the previously learned training points-with the key difference that, inspired by the concept of flat minima, we solve a minimax problem for a non-convex non-concave functional over an infinite-dimensional control space. We develop a projected gradient descent algorithm on the space of parameters that admits the structure of an infinite-dimensional Banach subspace. We show through simulations that this formulation enables the model to effectively learn new data points and gain robustness against control disturbance.
Recommended citation: Geometric Foundations of Tuning without Forgetting in Neural ODEs E Bayram, MA Belabbas, T Başar, in 2025 IEEE 64th Annual Conference on Decision and Control (CDC), IEEE, 2025. https://arxiv.org/abs/2509.18034
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.